Environmental Engineering Reference
In-Depth Information
(a)
(b)
(c)
1.6
1.6
3.4
Correlation (ρ) = -0.268
Correlation (ρ) = -0.251
Correlation (ρ) = -0.409
1.5
1.5
3.0
1.4
1.4
2.6
1.3
1.3
2.2
1.2
1.2
1.8
1.1
1.1
1.4
1.0
1.0
1.0
0
1
2
3
4
0
1
2
3
4
0
1
2
3
4
a
parameter (kPa
-1
)
a
parameter (kPa
-1
)
a
parameter (kPa
-1
)
Figure 1.11
Correlation between van Genuchten parameters for (a) sandy clay loam, (b) loam, and (c)
loamy sand. (From Phoon, K.K., Santoso, A., and Quek, S.T. 2010.
Journal of Geotechnical and
Geoenvironmental Engineering, ASCE
, 136(3), 445-455, reproduced with permission of the
American Society of Civil Engineers.)
sums of the components result in a normal random variable. This condition may not be
satisfied by actual bivariate data. There are alternate bivariate probability models. Some of
them are discussed in
Chapter 2
.
The bivariate model is a special case of the multivariate probability model. Nonetheless,
it is worthwhile covering this special case, because geotechnical engineering is replete with
correlations between two soil parameters, for example, between undrained shear strength
and PI, between OCR and cone tip resistance, and many others (Kulhawy and Mayne
1990). In addition, there are many curve-fitting procedures that involve two parameters.
The most well-known example is the cohesion and friction angles produced when a non-
linear failure envelope is fitted to a linear Mohr-Coulomb envelope. The cohesion is the
vertical intercept and the friction angle is the gradient of this linear envelope. A soil-water
characteristic curve can be fitted to a nonlinear van Genuchten containing two parameters
as shown in
Figure 1.11
. A third example is a two-parameter hyperbolic model for fitting
a load-displacement curve produced by a pile load test (Dithinde et al. 2011). Aside from
the practical significance of a bivariate model, it is a good introduction to the more general
multivariate model.
We use simulated bivariate standard normal data below to clarify the concept of the cor-
relation coefficient and how to estimate this index of dependency from data. To obtain the
simulated data, we initialize the pseudorandom sequence using randn('state', 13). Next,
we obtain two columns of independent standard normal data using
Z
= normrnd(0, 1,
n
,
2), where
n
is the sample size. The correlation matrix is entered as
C
= [1 δ
12
; δ
12
1], where
δ
12
is the Pearson correlation coefficient. The upper triangle Cholesky factor is computed
as
u
= chol(
C
) and two columns of correlated standard normal data are obtained from
X
T
=
Z
T
×
u
, where the superscript 'T' means the matrix transpose. Details on simulation of
correlated data are given in Section 1.3.4.
1.3.2 bivariate normal distribution
The bivariate normal distribution can be used to model two jointly distributed normal
random variables. Let us denote the vector [Y
1
Y
2
]
T
by
y
. This normal random vector is
described by a mean vector μ = [μ
1
μ
2
]
T
and a covariance matrix
C
:
(
)
(
)
COVY
,Y
COVY
,Y
σ
2
δ σσ
2
11
12
1
12
1
C
=
=
(1.35)
(
)
(
)
COVY
,Y
COVY
,Y
δσσ
σ
2
21
22
12
12
2



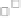






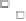





































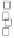











Search WWH ::

Custom Search