Database Reference
In-Depth Information
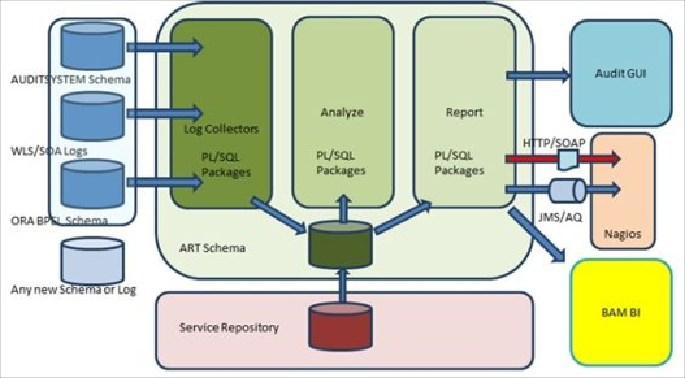
• The granularity of the records depends on the Trace/Audit level you have in your
system. The completeness of your data is the key factor to lend precision to your
analysis. A bit of data cleansing is sometimes required before analysis; with this,
you update and enhance incomplete records such as assuming a component's exit
time as the entry time of the next component in the invocation chain. The com-
plexity of this process can be quite high, depending on the complexity of your
compositions. A rule engine (custom, Oracle, or any other) is employed for mak-
ing decisions based on functional policies and SLA metrics that are stored in
ESR.
• The final results are delivered into the last component, usually a Report schema
with a clean log that contains conclusions and resolution suggestions. This data is
consumed by any dashboards, consoles, and reporting tools, both standard and
custom. This is also the source for a dedicated process that will be responsible for
performing complex recovery actions and compensations. The simple implement-
ation can be the Adapter (on SCA, the BPEL or Mediator will do) checking for
the resolution flag and the name of the process/composition to execute. A Java
process reading AQ will increase the resiliency as it will comply with design rules
9 and 15. Needless to say that most of the operations in the technical and func-
tional monitoring described in the preceding bullet list shall be performed on the
DB side to make it more simple, fast, and resilient (less components involved);
Oracle DB works perfectly well with AQs and is the top choice for BAM and
Oracle BI.
Search WWH ::

Custom Search