Information Technology Reference
In-Depth Information
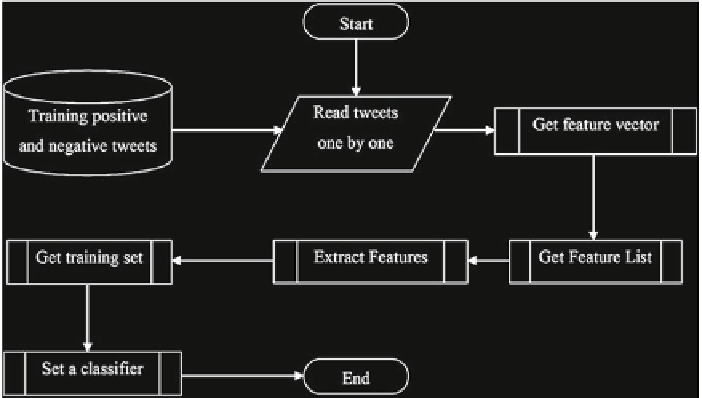
Fig. 2.5
Flowchart of training process
Step
4 After producing the feature list, the next step is extracting features. In a sample
tweet such as “He has changed in his bag,” the feature words to be extracted are
“changed', “bag,” “has,” and “he.” Then, these feature words are examined whether
they are included in the feature list words in order to extract features.
Step
5 Features are applied to the classifier. To sum up, a flowchart of the training
process is set as it can be observed from Fig.
2.5
.
2.3.3.3 Automated Tweet Collecting and Classification
The tweet collector script presented in the subsection of tweet collecting and the
classifier script presented in the subsection of sentiment analysis above are combined
as a new Python script to produce an automated tweet collecting and classification
system. First, the script trains the Maximum Entropy classifier and Naïve Bayes
classifier with the training-modified datasets. Second, the system collects tweets
about the four companies from the users located in several cities, and lastly, the
script classifies tweets as positive or negative, and then it stores them into database.
This script is converted into an executable file format to run it hourly as a background
process on web server. Another reason why we converted it into the executable file
format is to be able to run it without requiring a Python compiler installation. Below,
Fig.
2.6
shows the flowchart of this executable file.
Search WWH ::

Custom Search