Information Technology Reference
In-Depth Information
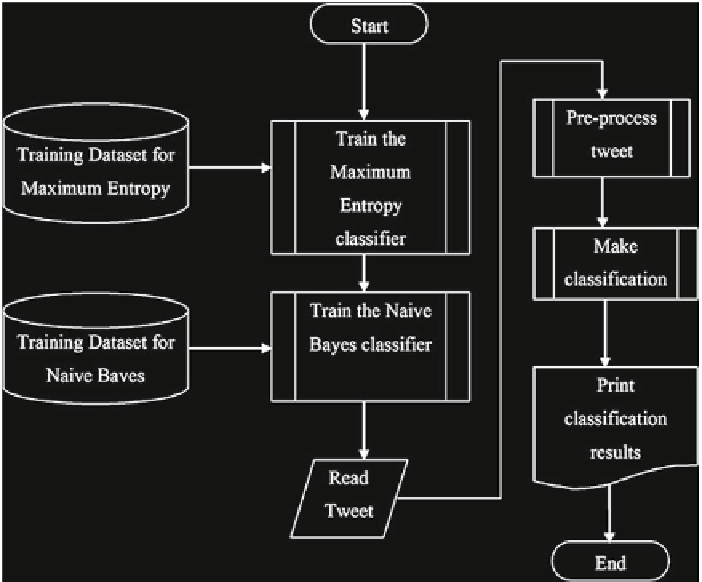
Fig. 2.4
Flowchart of classifier Python script
datasets which are presented in the subsection of the hand-classified data set and then
read the given tweets. Second, script preprocesses these tweets, and then, the tweets
are classified as positive or negative (Fig.
2.4
).
Step by Step Training Process
Step
1 To automatically classify a tweet, first the classifier needs to be trained. To do
that, a list of hand-classified tweets is required. 512 hand-classified tweets are used to
train the Maximum Entropy classifier. 1,035 hand-classified tweets are used to train
the Naïve Bayes Classifier. The reason of using the 512 hand-classified tweets rather
than 1,035 forMaximumEntropy classifier is to avoid the slow training process. Even
when 512 tweets are used, the training process with 40 iterations takes unfeasible
duration for an online system.
Step
2 A feature vector needs to be created. The feature vector is the most crucial
item in employing a classifier. A good feature vector can foresee how successful the
results of the classifier will be.
Step
3 After creating the feature vector, a sequenced feature list is produced. The
most frequently used word is the first member of the feature list array. The feature
list is used to train classifiers.
Search WWH ::

Custom Search