Information Technology Reference
In-Depth Information
(a)
(b)
1
1
Main1 (audio only)
Main2 (visual only)
Main3 (affect only)
Main4 (audio + visual + affect)
Gen1 (audio only)
Gen2 (visual only)
Gen3 (affect only)
Gen4 (audio + visual + affect)
0.9
0.9
0.8
0.8
0.7
0.7
0.6
0.6
0.5
0.5
0.4
0.4
0.3
0.3
0.2
0.2
0.1
0.1
0
0
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Recall
Recall
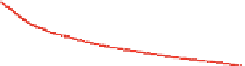
Fig. 11.5
Precision-Recall curves
a
on the Hollywood movie dataset (Area Under Curve (AUC) for
Main1: 0.2985, Main2: 0.2757, Main3: 0.2066, and Main4: 0.3255), and
b
on the Web video dataset
(AUC for Gen1: 0.5606, Gen2: 0.4447, Gen3: 0.4500, and Gen4: 0.5571) using different represen-
tations (Main/Gen1:
audio-only
, Main/Gen2:
visual-only
, Main/Gen3:
affect-only
and Main/Gen4:
multimodal
)
Table 11.5
The Mean Average Precision (MAP) and MAP@100 of our best-performing method
(i.e., the one with a
multimodal
representation), the work of Penet et al. [
30
] and an SVM-based
unique violence detectionmodel (i.e., no feature space partitioning) on the Hollywoodmovie dataset
Method
MAP
MAP@100
Our method (multimodal)
0.422
0.539
Penet et al. [
30
]
0.353
0.448
SVM-based unique violence detection model
0.257
0.356
which can be inferred from the overall results is that the average precision variation
of the method is high for movies of varying violence levels.
In Fig.
11.5
, the precision-recall (PR) curves of our method with different video
representations are provided. As seen from the resulting PR curves, our method
performs better on short web videos (Fig.
11.5
b).
Table
11.5
provides a comparison of our best performing method (i.e., the one
with a
multimodal
representation) in terms of MAP and MAP@100 metrics with
the method introduced in [
30
] and an SVM-based unique violence detection model
(i.e., a model where no feature space partitioning is performed). We can conclude
that our method provides promising results and more importantly, outperforms the
SVM-based detection method where the feature space is not partitioned and all
violent and nonviolent samples are used to build a unique model.
Finally, we can observe from the overall results provided in this section that our
method performs better when violent content is better expressed in terms of audio
features (a typical example would be a gun shot scene). This is an indication that
we need more discriminative visual representations for detecting violent content in
movies and short web videos to further improve the performance of our method.





































































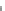



















































































Search WWH ::

Custom Search