Information Technology Reference
In-Depth Information
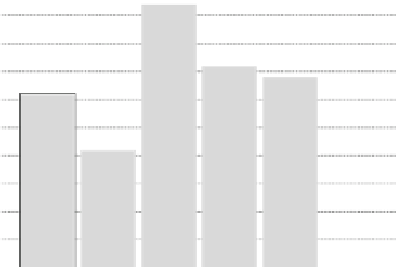
the user model without the purchase history, we can see that it is possible to deduce
preferences of a user for certain types of clothing. The best approach, of the single
approaches, is the KNN approach, which outperforms the others by quite a big
margin. The results for KNN and Naïve Bayes can be explained by the type of data.
Most of the attributes in the dataset are numeric. As Naïve Bayes cannot deduce any
information out of numbers, it is reasonable that Naïve Bayes performs weak. The
KNNapproach uses Euclidean distance as the similaritymeasure. Euclidean distance,
opposite to Naïve Bayes can cope with numeric variables. Thus, the performance
of KNN is quite good. Our CBR approach focuses on learning preferences for the
different features by taking into account previous purchases. We handle all features
equally, not making differences between numbers and text. We only weigh the value
positively or negatively. Thus, we also do not work with similarity of numeric values,
but we are also not ignoring them as Naïve Bayes does.
Taking a closer look at the accuracy measure, we first see, that the “all returns”
algorithm performs quite well. This is of course expected and shows that the chosen
measure is an important factor in an evaluation. What we also see, and why we added
the accuracy measure to the evaluation, is that our CBR approach performs worst.
As we optimized it, tweaking the threshold to predict kept items, this is expected as
well. The performance of KNN is the best, also in the accuracy measure, leading to
the conclusion that there are certain item attributes, possibly numeric attributes, that
contain information allowing the prediction if an item is kept or not. The ensemble
is together with the KNN the top approach with respect to accuracy.
The evaluation shows that learning preferences is a good approach to improve
the rate of items kept (meaning the user bought it). But we also see that our CBR
approach misses some of the information contained in the dataset. Therefore, next
steps have to include an extension of the CBR that takes and handles attributes more
differentiated. As the results induce, different attributes have different information
0.50
0.45
0.40
0.35
0.30
0.25
0.20
0.15
0.10
0.05
0
Fig. 8.9
Results for precision measure of the different approaches. CBR is the approach discussed
in this chapter








Search WWH ::

Custom Search