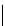Database Reference
In-Depth Information
For example, in the case of the inline approach, the CSP of
Figure 18.2
guar-
antees the holding of these requirements
1
. Another possibility is to apply a post-
processing algorithm that will increase the support of the infrequent itemsets of
Layer 3 in the sanitized database D, such that they move to Layer 2 (thus increase
the concentration of itemsets in the layer that contains the sensitive ones). On the
negative side, it is important to mention that all these methodologies for increasing
the safety of the sensitive knowledge have as an effect the decrement of the qual-
ity of the sanitized database, with respect to its original counterpart. This brings up
one of the most commonly discussed topics in knowledge hiding: hiding quality vs.
usability of the sanitized database, offered by the hiding algorithm.
Table 18.1: An example of a sanitized database D produced by the inline algorithm
[23], which conceals the sensitive itemsets S =fB;CDg at a frequency threshold of
mfreq = 0:3.
A
B
C
D
1
1
0
0
1
1
0
0
1
0
0
0
1
0
0
0
0
0
0
1
1
0
1
1
0
0
1
1
0
0
1
0
1
0
0
0
0
0
0
1
Figure 18.1(ii)
demonstrates the operation of the layered approach of [25] for
the example database of
Table 18.1.
As expected, due to the minimum harm that
is introduced by the exact hiding algorithms, both sensitive itemsets B and CD are
located just under the borderline. In this example, the size of Layer 1 is zero (i.e.,
y = 0). Based on the estimator E, the probability of an adversary to identify the
sensitive knowledge is found to be 2/3 when using x = 1 (equivalently when mining
the database using msup = 2). Since the probability of sensitive knowledge disclo-
sure is high, the owner of the data could either (i) use the CSP formulation of Figure
18.2
to constraint the support of the sensitive itemsets to at most 1, or (ii) apply a
methodology that increases the support of some of the itemsets in Layer 3 so as to
move to Layer 2 (i.e., obtain a support of 2). Both approaches are bound to introduce
extra distortion to the original database D
O
from which D was produced, but will
also provide better protection of the sensitive knowledge.
1
We should also point out that the owner of the data can decide to hide different sensitive itemsets
at a different degree, thus consider some of these itemsets as more sensitive than the others. To
achieve that he/she can properly adjust the support threshold (i.e., the right side of the inequalities)
in the corresponding constraints of the CSP of Figure 18.2, involving these sensitive itemsets.