Game Development Reference
In-Depth Information
FIGURE 12.5
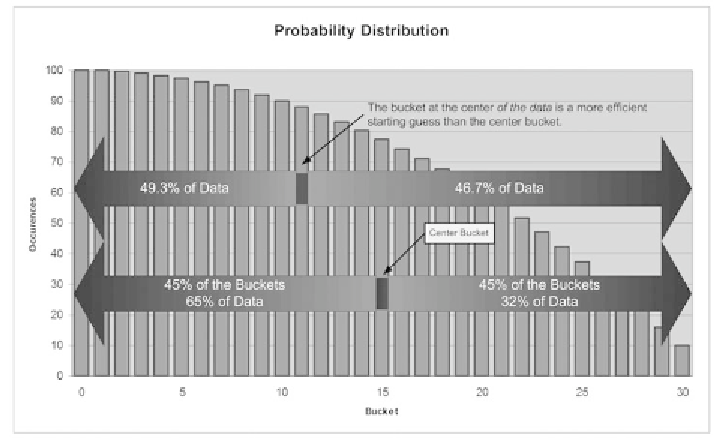
We can improve the performance of searching for the selected bucket
by starting in the middle of the data distribution rather than the middle bucket.
Most of the data occurrences are on the left side of the histogram. Therefore, we
bias our search to that side by starting with bucket 11 rather than bucket 15.
In this example, the edge of bucket 30 is 2155. Half of that is 1077. The value
1077 falls into bucket 11. If we examine the bucket
below
number 11, we find that
the edge of bucket 10 is 1062. That tells us that 49.3% (1062/2155) of the values are
in bucket 10 or below. On the other hand, the edge of bucket 11 is 1149. There are
1005 (2155 - 1149) numbers
above
bucket 11. That represents 46.7% of the total.
(Bucket 11 is the missing 4.1%.) This means, if the answer is
not
bucket 11, we have
about an even chance of being either too high or too low.
To accomplish this, we need a new way to determine our starting bucket. As we
explained, this is simply a matter of dividing the highest edge value in half and then
searching for it via the original, slightly inefficient method. We then store that value
for use in all of our regular searches.
We don't need to do this every time we search. If we did, it would be very inef-
ficient anyway because we would be searching twice for every real search. As long
as the data does not change, the suggested starting point does not change. In fact,
because the binary search is so fast, as long as the data doesn't change
much
, we can
still use that suggested starting point.