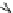Database Reference
In-Depth Information
Fig. 3.1
FP-tree for
transaction database in
Table
3.1
root
Header table
f:4
c:1
item
head of node-links
f
c:3
b:1
b:1
c
a
b
a:3
p:1
m
p
m:2
b:1
p:2
m:1
Second, the root of a tree, labeled with “
null
” is created. Scan the
DB
the second
time. The scan of the first transaction leads to the construction of the first branch
of the tree:
(
f
: 1), (
c
: 1), (
a
: 1), (
m
: 1), (
p
:1)
. Notice that the branch is
not ordered in
as in the transaction but is ordered according to the
order in the
list
of frequent items. For the second transaction, since its (ordered)
frequent item list
f
,
a
,
c
,
m
,
p
f
,
c
,
a
,
b
,
m
shares a common prefix
f
,
c
,
a
with the existing
path
, the count of each node along the prefix is incremented by 1, and
one new node (
b
: 1) is created and linked as a child of (
a
: 2) and another new node
(
m
: 1) is created and linked as the child of (
b
: 1). Remaining transactions can be
inserted similarly.
To facilitate tree traversal, an item header table is built, in which each item points,
via a head of node-link, to its first occurrence in the tree. Nodes with the same item-
name are linked in sequence via node-links. After scanning all transactions in
DB
,
the tree with the associated node-links is shown in Fig.
3.1
.
The FP-tree built in Example 2 has some nice properties as follows: (1)
FP-
tree contains complete information of TDB w.r.t. frequent itemset mining
: every
transaction in
TDB
is mapped onto one path in the FP-tree, and the frequent itemset
information is completely stored in the tree; (2)
FP-tree is a highly compact structure
:
since there are often a lot of sharing of frequent items among transactions, the size of
the tree is usually much smaller than its original database; and (3)
there is a node-link
property
: for every frequent item
x
, all transactions containing
x
can be obtained by
following
x
's node-links starting from
x
's head in the FP-tree header table.
Based on this compact structure, FP-growth mines the complete set of frequent
itemsets as follows.
f
,
c
,
a
,
m
,
p
Example 2
(FP-growth) Let us examine the mining process based on the constructed
FP-tree (Fig.
3.1
).
According to the list of frequent items, the complete set of frequent itemsets can
be divided into six subsets without overlap: (1) frequent itemsets having item
p
; (2)