Database Reference
In-Depth Information
2
1
0
0
1
2
3
x dimension
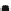
Fig. 16.7
Grid with density-preserving borders: to guarantee detection of all density-based subspace
clusters, the grid is enhanced with borders (
gray shaded
) at the top of each cell in each dimension.
These borders have exactly the size of the area for the density assessment (circles around points in
the clusters at the
bottom right
), so that an empty border means that no cluster extends across these
two cells
EDSC [
11
] is used, which consists of a traditional equal-width grid, plus density-
preserving borders. Figure
16.7
illustrates the general idea: the density-preserving
borders make it possible to determine whether points in one cell are potentially
density-connected to those in a neighboring cell. They are the size of the area used
for density assessment (circles around points in the figure). If a subspace cluster
extends across one of these borders, this border must be non-empty. If that should
be the case, these cells need to be merged during mining.
A SCY-tree is constructed, which similar to item frequency counts in FP-trees
contains counts of the number of points in a particular grid cell. In addition, marker
nodes are introduced to signal that the border between neighboring cells is non-
empty. An example is given in Fig.
16.8
. As we can see in this example, the ten
points that are in the bottom '0' slice of the
y
-dimension (leftmost node under the
root in the tree), fall into three different intervals in the
x
-dimension: two in cell
'1', three in cell '2', and five in cell '3' (three child nodes). Additionally, a node
marks the presence of one or more points in the border of cell '2' by a special node
without any count information. Similar to FP-Growth, it is then possible to mine
subspace clusters in a depth-first manner. Different levels of the index correspond
to the dimensions in which these cells exist. As opposed to frequent itemset mining,
neighboring nodes are merged if they contain cells that are potentially part of the
same cluster.
3.2
Subspace Search
Subspace search based on frequent pattern mining concepts has been applied both in-
dependently of specific clustering algorithms, as well as integrated in some clustering