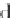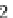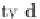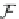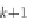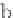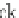Database Reference
In-Depth Information
Fig. 2.3
The
Apriori
algorithm
The computationally intensive procedure in this case is the counting of the candi-
dates in
. Therefore, a number of
optimizations and data structures have been proposed in [
1
] (and also the subsequent
literature) to speed up the counting process. The data structure proposed in [
1
]is
that of constructing a
hash-tree
to maintain the candidate patterns. A leaf node of the
hash-tree contains a list of itemsets, whereas an interior node contains a hash-table.
An itemset is mapped to a leaf node of the tree by defining a path from the root to the
leaf node with the use of the hash function. At a node of level
i
, a hash function is
applied to the
i
th item to decide which branch to follow. The itemsets in the leaf node
are stored in sorted order. The tree is constructed recursively in top-down fashion,
and a minimum threshold is imposed on the number of candidates in the leaf node.
To perform the counting, all possible
k
-itemsets which are subsets of a transaction
are discovered in a
single
exploration of the hash-tree. To achieve this goal
all possible
paths in the hash tree that could correspond to subsets of the transaction, are followed
in recursive fashion, to determine which leaf nodes are relevant to that transaction.
After the leaf nodes have been discovered, the itemsets at these leaf nodes that are
subsets of that transaction are isolated and their count is incremented. The actual
selection of the relevant leaf nodes is performed by recursive traversal as follows. At
the root node, all branches are followed such that
any
of the items in the transaction
hash to one of branches.At a given interior node, if the
i
th item of the transaction was
last hashed, then all items
following it
in the transaction are hashed to determine the
possible children to follow. Thus, by following all these paths, the relevant leaf nodes
in the tree are determined. The candidates in the leaf node are stored in sorted order,
and can be compared efficiently to the hashed sequence of items in the transaction to
determine whether they are relevant. This provides a count of the itemsets relevant
to the transaction. This process is repeated for each transaction to determine the final
support count for each itemset. It should be pointed out that the reason for using
a hash function at the intermediate nodes is to reduce the branching factor of the
hash tree. However, if desired, a trie can be used explicitly, in which the degree of a
C
k
+
1
with respect to the transaction database
T