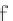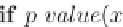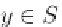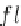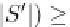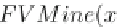Database Reference
In-Depth Information
The next step is to mine common sub-feature vectors that are also significant.
Algorithm 16 presents the FVMine algorithm which explores closed sub-vectors
in a bottom-up, depth-first manner. FVMine explores all possible common vectors
satisfying the significance and support constraints.
With a model to measure the significance of a vector, and an algorithm to mine
closed significant sub-feature vectors, we integrate them to build the significant
graph mining framework. The idea is to mine significant sub-feature vectors and
use them to locate similar regions which are significant. Algorithm 17 outlines the
GraphSig
algorithm.
The algorithm first converts each graph into a set of feature vectors and puts all
vectors together in a single set
D
(lines 3-4).
D
is divided into sets, such that
D
a
contains all vectors produced from RWR on a node labeled
a
. On each set
D
a
,
FVMine is performed with a user-specified support and
p
value thresholds to retrieve
the set of significant sub-feature vectors (line 7). Given that each sub-feature vector
could describe a particular subgraph, the algorithm scans the database to identify the
regions where the current sub-feature vector occurs. This involves finding all nodes
labeled
a
and described by a feature vector such that the vector is a super-vector of
the current sub-feature vector
v
(line 9). Then the algorithm isolates the subgraph
centered at each node by using a user-specified radius (line 12). This produces a
set of subgraphs for each significant sub-feature vector. Next, maximal subgraph
mining is performed with a high frequency threshold since it is expected that all of
graphs in the set contain a common subgraph (line 13). The last step also prunes out
false positives where dissimilar subgraphs are grouped into a set due to the vector
representation. For the absence of a common subgraph, when frequent subgraph