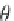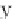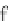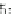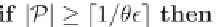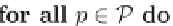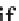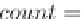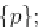Database Reference
In-Depth Information
infrequent at some timepoint. Their method, however, does not allow for the user
to chose the size of the error, so it many be large. Moreover, errors can compound
as
estDec
builds larger itemsets from smaller ones. The several set-based computa-
tions can also be expensive. This estimation method, however, is independent of the
damped window method. Other works have also used the damped window but with
different counting algorithms [
31
,
47
,
71
].
Sliding Windows
Jin and Agarwal [
40
] introduce an algorithm that provides the
same result quality guarantee as LOSSY COUNTING, but uses much less memory.
Also similar to LOSSY COUNTING, it processes the data stream one batch at a time. It
is presented as a sliding window method, but it could be modified to preserve results
from one earlier batches to combine them with the current batch.
They propose a two-stage (single pass)
hybrid
approach. In the first stage, they
employ a method for efficiently finding potentially frequent 2-itemsets that is more
memory efficient that Aprori. Second, they apply the Apriori property to generate
the potential
i
-itemsets, for
i>
2. This approach finds a set of potential frequent
itemsets, which is guaranteed to contain all the
true
frequent itemsets, in a single
pass of the stream.
Stage
one
is
an
extension
of
the
work
by
Karp,
Papadimitriou
and
Shenker (KPS) on finding frequent elements (or 1-itemsets) [
42
].
Formally,
given
a
sequence
of
length
N
and
a
threshold
θ
(0
<θ<
1),
the goal of their work is to determine the elements that occur with frequency greater
than
Nθ
, without spending the memory to remember all
N
elements.