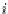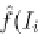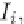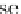Database Reference
In-Depth Information
The FDPM algorithm uses this bound as follows. A pattern
X
is
potentially fre-
quent
if
f
(
X
)
≥
θ
−
n
. For target levels
θ
and
δ
, Yu et al. show that the a required
number of transactions per batch is
2
+
2ln(2
/δ
)
θ
n
0
=
(9.4)
For simplicity, we assume that the transaction sequence has been decomposed into
an itemset sequence
I
={
I
1
,
I
2
,
I
3
,
...
}
.
The size of
n
0
can be set by the amount of available memory. An interesting property
of this algorithm is that when
n<n
0
, the result set will be exact. When
n
is just over
n
0
, then the error will be at a maximum given by Eq.
9.3
.As
n
continues to increase,
the error will tend to decrease.
Comparing Lossy Counting and FPDM
Both algorithms logically partitioned the
data stream into equally-sized segments and find the potentially frequent itemsets for
each segment. They aggregate these locally frequent itemsets and further prune the
infrequent ones. However, the number of transactions in each segment as well as the
method to define potentially frequent itemsets is different for these two methods. In
LOSSY COUNTING, the number of transactions in a segment is
, and an itemset
which occurs more than once in a segment is potentially frequent. In FDPM, the num-
ber of transactions in a segment is
n
0
, where
n
0
is the required number of observations
in order to achieve the Chernoff bound with the user-defined parameter
δ
.
To theoretically estimate the space requirement for both algorithms, we consider
each transaction including only a single item, and the number of transactions in the
entire data stream is
1
/
)) to find fre-
quent items (1-itemsets). Thue, in order to reduce its error, Lossy Count will need
to increase its memory usage. FPDM-1 (the simple version of FPDM on finding fre-
quent items) will need
O
((2
|
D
|
. LOSSY COUNTING will take
O
(1
/log
(
|
D
|
+
2
ln
(2
/δ
))
/θ
). If the user chooses to set the confidence
level
δ
, then there is no direct control over the error rate. However, the error rate will
decrease as
n
increases.
Note that different approaches have different advantages or drawbacks. For in-
stance, for the false positive approach, if a second pass is allowed, we can easily
eliminate false positives. For the false negative approach, we can have a small result