Database Reference
In-Depth Information
Database
(
n
classes)
Encode
unseen
transactions
Split
per class
Apply
K
RIMP
Code table
per class
Shortest
code wins!
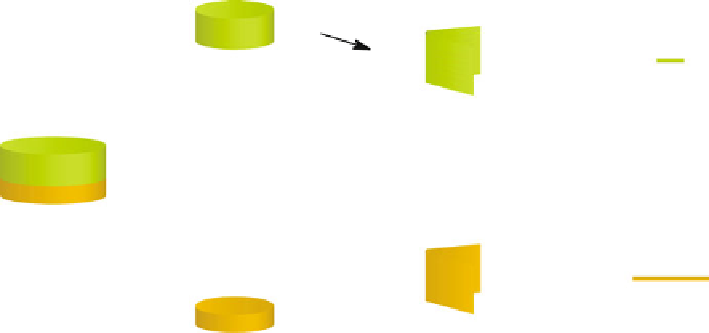
Fig. 8.3
The code table classifier in action
Lemma 8.14
, sampled from two
different distributions, CT
1
and CT
2
the optimal code tables for
Let
D
1
and
D
2
be two bags of tuples from
T
D
1
and
D
2
, and t
an arbitrary tuple over
T
. Then, by Lemma 8.13 we have
L
(
t
|
CT
1
)
>L
(
t
|
CT
2
)
⇒
P
(
t
|
D
1
)
<P
(
t
|
D
2
)
.
Hence, the Bayes optimal choice is to assign
t
to the distribution that leads to the
shortest code length.
5.1.2
The Code Table Classifier
The above suggests a straightforward classification algorithm based on code tables.
This classification scheme is illustrated in Fig.
8.3
.
The classifier consists of a code table per class. Given a database with class labels,
this database is split according to class, after which the class labels are removed from
all tuples. Then, some induction method is used to obtain a code table for each single-
class database. When the per-class compressors have all been constructed, classifying
unseen tuples is trivial: simply assign the class label belonging to the code table that
provides the minimal encoded length for the transaction.
Note that this simple yet effective scheme requires a code table to be able to
compress any possible tuple, i.e., it should be possible to compute
L
(
t
|
CT
) for any
t
. For this it is important to keep all 'primitive' patterns in the code table, i.e.,
those that are in the 'empty' code table. Further, to ensure valid codes all patterns
should have non-zero usage, which can be achieved by, e.g., applying a Laplace
correction: add one to the usage of each pattern in the code table.
Results of this scheme on itemset data, using KRIMP [
37
] and PACK [
62
], show this
simple classifier performs
on par
with the best classifiers in the literature, including
∈
T