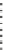Database Reference
In-Depth Information
Fig. 5.2
An example of swap
randomization
i
j
i
j
x
x
1
0
0
1
y
y
0
1
1
0
a
b
before swap
after swap
1 s and two are 0 s, and both ones are in opposite corners, see Fig.
5.2
, then we
swap
D
ix
with
D
iy
and
D
jx
with
D
jy
. It is easy to see that the new dataset will have
the same row and column margins. By repeating this process many times, i.e., until
the MCMC chain has converged, we can generate random datasets simply by starting
the random walk from the input dataset. Note that in practice, however, we do not
know when the MCMC chain has converged, and hence have to use a heuristic
number of steps to reach a 'random' point in
.
By sampling many random datasets, we can assess how significant a score ob-
tained on the original data is in light of the maintained background knowledge by
computing an empirical
p
-value—essentially the fraction of sampled datasets that
produce higher support of an itemset
X
than the original support. The number of
sampled datasets hence determines the resolution of the
p
-value.
In short, the (swap-)randomization and MaxEnt modelling approaches are very
related. The former can be used to sample data that maintains the background knowl-
edge exactly, while in the latter information is only maintained on expectation. The
latter has the advantage that exact probabilities can be calculated. By sampling
random data, whether by randomization or from a MaxEnt model, we can obtain
empirical p-values—also for cases where by the nature of the score we're looking
at (e.g., clustering error, classification accuracy, etc), it is impossible, or unknown,
how to calculate exact values given a probabilistic model.
5
Dynamic Background Models
So far, we have covered only
static
scores. While within this class method have been
proposed that are increasingly good at correctly identifying uninteresting patterns,
they can only do so for individual patterns and with regard to a
static
background
model. As such, when regarding the top-
k
result, we may still find patterns that are
mostly variants of the same (significant) theme. In this chapter we turn our attention
to models that explicitly take relationships between patterns into account.