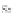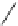Database Reference
In-Depth Information
Fig. 4.6
Two strands
U
1
and
U
2
and their substring relation
graph
After finding all the closed valid strands in the first step, the algorithm computes
the support set for each frequent approximate substring. The idea of grouping the
strands is the following. Given the set
X
of all closed valid strands, we construct a
substring relation graph
G
from
X
. The vertex set is all the substrings in the strands
of
X
, each vertex representing a distinct substring. There is an edge between two
substrings if and only if the Hamming distance between two substrings is within the
error tolerance. Since all the substrings in one valid strand share the same distance
among each other and the distance is within the error tolerance, all corresponding
vertices in
G
form a clique. After scanning all the strands in
X
, we would construct
a graph
G
which is a union of cliques. Then a substring is a frequent approximate
substring if and only if the degree of the corresponding vertex is greater than or equal
to the minimum frequency threshold, as illustrated in Fig.
4.6
.
Large Graph Pattern
In [
33
], a piece-wise pattern-merge style mining algorithm
targeted at large graph patterns, called
SpiderMine
, has been proposed based on
the concept of a spider, which is critically important in both identifying and faster
reaching the long patterns. Formally, an
r
-spider is defined as follows.
Definition 4.9
[
r
-spider]
Given a frequent pattern P in graph G and a vertex
u
V
(
P
),
if P is r-bounded from u, we call P an r-spider with head u
.
The
SpiderMine
algorithm is designed to solve the problem of mining approxi-
mate top-
K
long patterns with bounded diameter in a single large graph. The basic
challenges for the problem are two-fold: (1) How to identify the top-
K
largest patterns
with a high probability? and (2) How to quickly reach the long patterns?
As trying all the possible growth paths is unaffordable, one has to identify a small
set of highly potential ones which would lead to the long patterns with good chance.
The
SpiderMine
solution is based on the following observation:
long patterns are
composed of a large number of small components which would eventually become
connected after certain rounds of growth.
The more of such small components of a
long pattern we can identify, the higher chance we can recover it. Thus,
SpiderMine
first mines all such small frequent patterns, which are the
spiders
as defined in
Definition
4.9
. Compared with small patterns, long patterns contain far more spiders
as their subgraphs. It follows that if one picks spiders uniformly at random from the
complete spider set, the chance that one would pick some spider within a long pattern
is accordingly higher. Moreover, if the algorithm carefully decides on the number of
spiders to be randomly picked, the probability that multiple spiders within
P
would
be chosen is higher if
P
is a larger pattern than a smaller one. Denote the set of all
∈