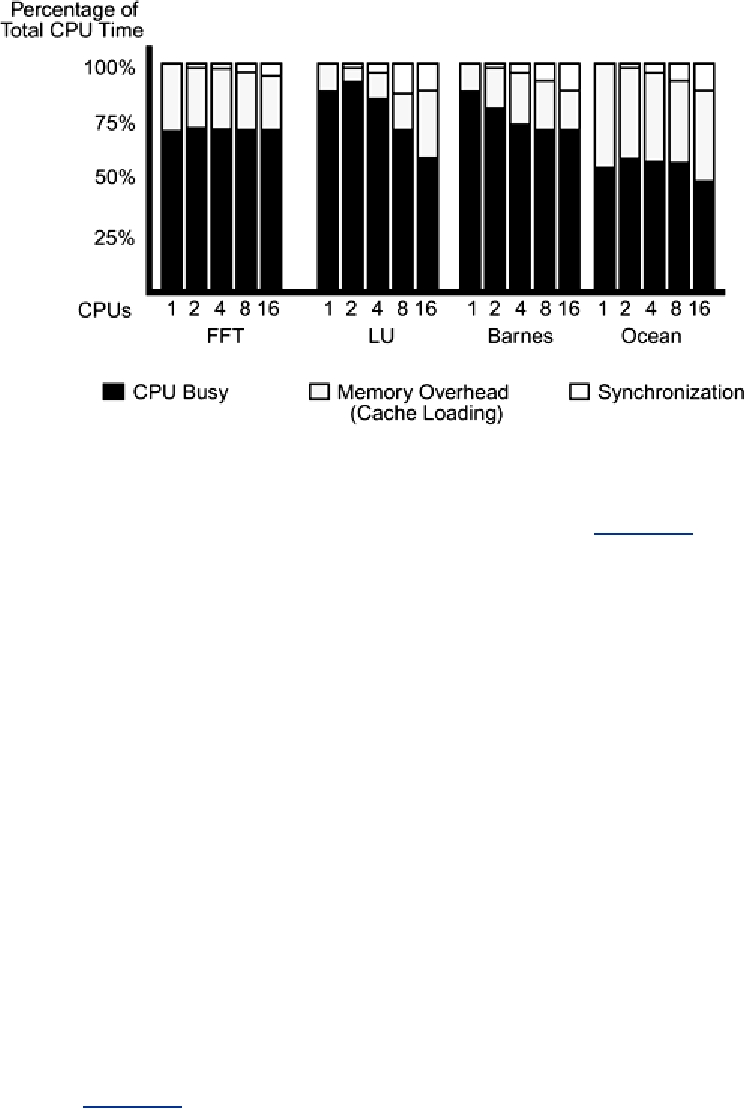
Superlinear Speedup
In a very small number of programs, such as Ocean on two and four CPUs (Figure 15-2), it is
possible to see speedups slightly better than linear. This is a result of having more cache and
possibly reducing overhead because of fewer context switches. It's nice if you get it, but don't
expect it.
Timing Threaded and Nonthreaded Programs
In our measurements, we compare the runtime of identical code that creates different numbers of
threads, appropriate to the available CPUs. This isn't really fair, because we're including the
synchronization overhead (and possibly a less efficient algorithm) for the one-CPU case, which
doesn't need that synchronization.
Unfortunately, for any real program, it's far too complex to implement, optimize, and maintain two
different programs (the PSR argument again). Most ISVs ship a single binary and simply run
suboptimally on uniprocessors. You may console yourself (and your marketing department) by
noting that you can probably find more performance improvement in the techniques mentioned
above than you can in writing a uniprocessor-only version.
Amdahl's Law
Amdahl's law (Figure 15-4) states: If a program has one section that is parallelizable, and another
section that must run serially, the program execution time will asymptotically approach the time
for the serial section as more CPUs are added.
Figure 15-4. Amdahl's Law: Time(total) = Time(serial) + Time(parallel) /
Number_of_CPUs
Search WWH :