Making malloc() More Concurrent
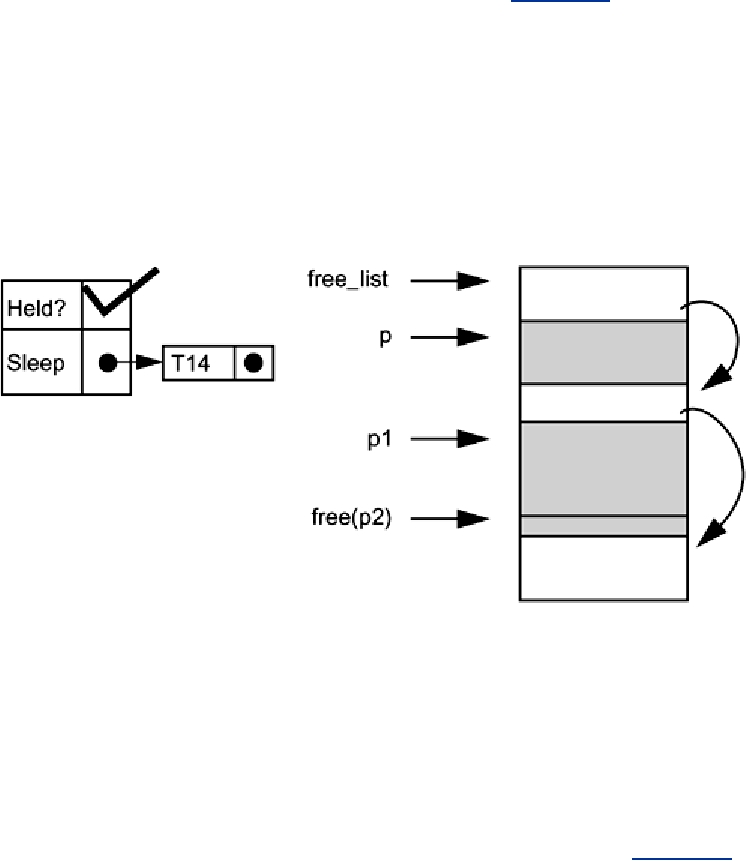
The implementation of malloc() on Solaris 2.5 is quite simple (Figure 12-1). There's one global
lock that protects the entire heap. When a thread calls either malloc() or free(), it must hold
that lock before doing the work. It's a simple, effective design that works fine in most programs.
When you have numerous threads calling malloc() often, you can get into a performance
problem. These two functions take some time to execute and you can experience contention for
that one lock. Let's consider other possible designs. Keep in mind that we are not going to be
changing the definition of malloc(), nor will we change the API. We are only going to change
the implementation underneath.
Figure 12-1. Current Solaris Implementation of malloc()
Using Thread-Specific Data to Make malloc() More Concurrent
When used sparingly, a simple mutex works fine. But when called very often, this can suffer from
excessive contention. The TSD solution is a possibility, but it introduces some problems of its
own.
What if T2 mallocs some storage and T1 frees it? How does T1 arrange to return that memory to
the correct free list? [Because free() will glue adjacent pieces of freed memory together into a
single large piece, the free() must be called with the original malloc area; see Figure 12-2.] If
T2 exits, who takes care of its malloc area? If an application creates large numbers of threads but
seldom uses malloc(), it will be creating excessive numbers of malloc areas.
Figure 12-2. Threads with Individual TSD malloc() areas
Search WWH :